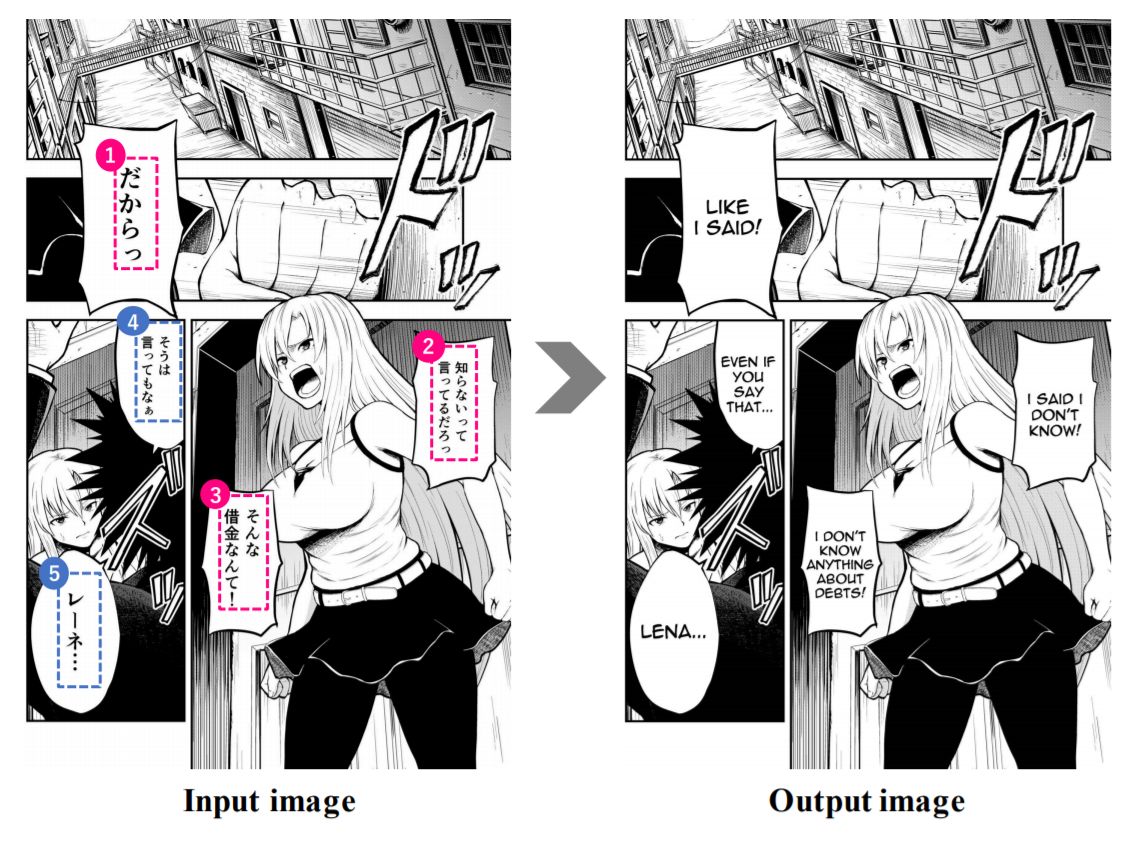
A recent paper by Japanese researchers shows how they built a system to fully automate the process of translating manga from Japanese to English. Given a manga page, the system translates and replaces the original Japanese text with English and formats it nicely on the page.
Contextual Information from Manga Images
One of the novel innovations of this recent paper titled “Towards Fully Automated Manga Translation” by Japanese researchers Ryota Hinami et al. (which is to be published at AAAI 2021), is that it is able to translate Japanese text in speech bubbles that cannot be translated without using context information. This context information includes things like texts in other speech bubbles, the gender of speakers from manga images and the order of text inferred from the structure of the manga page.
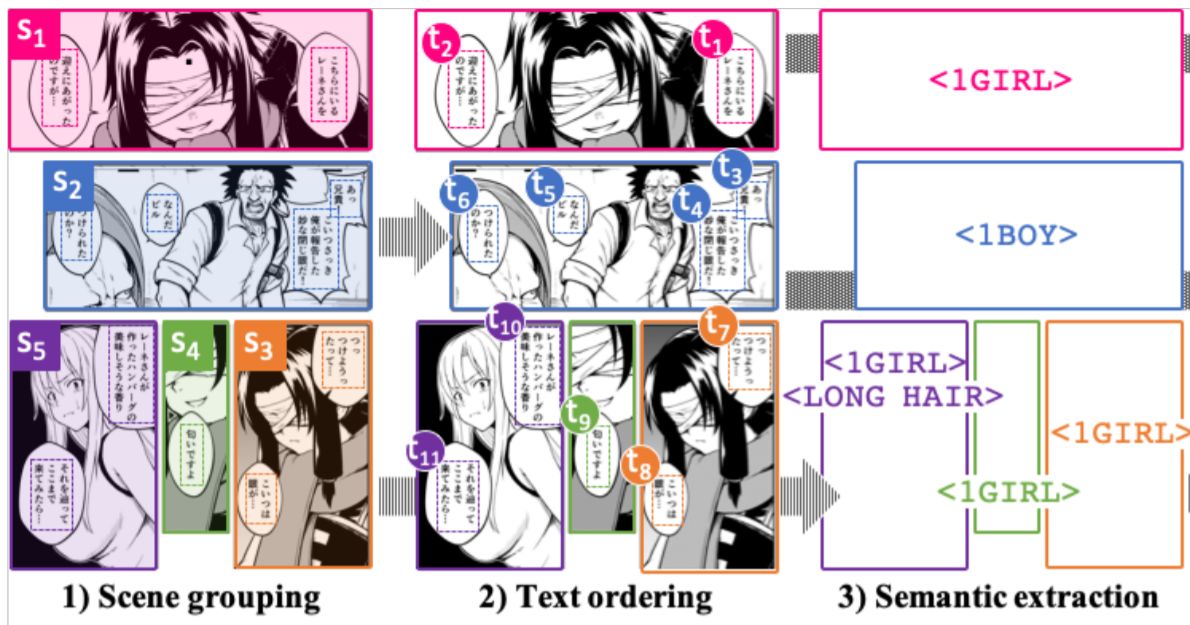
To extract multimodal context (text and images), the system:
- Groups texts into scenes (S1, S2, …)
- Orders the texts according to reading order (t1, t2, …)
- Extracts visual semantic information (1boy, 1girl, long-hair) with illustration2vec.
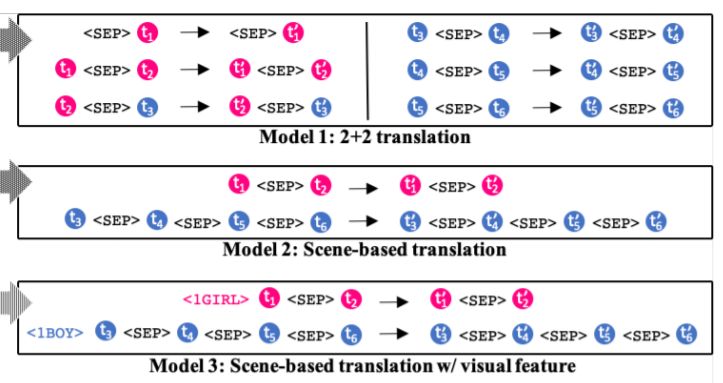
With the multimodal context the authors then build 3 different models (detailed in the figure below) and evaluated them. Model 3 which includes scene and manga image information performs the best.
Model 3 scored the best in the evaluation with human users (which is always a better test than automatic metrics). Also the authors did this evaluation with the full translated pages instead of just the plain text.
Manga translation differs from plain text translation because the content of the images influences the “feeling” of the text. To examine how readers actually feel when reading a translated page, we conducted a manual evaluation of translated pages instead of plain texts.
Unsupervised Extraction of A Large Parallel Manga Corpus
There already exists large amounts of manga translated from Japanese to English (and other languages as well). The authors also propose a system to use a Japanese manga and its English counterpart to build a domain-specific large parallel corpus to train Neural Machine Translation (NMT) systems.
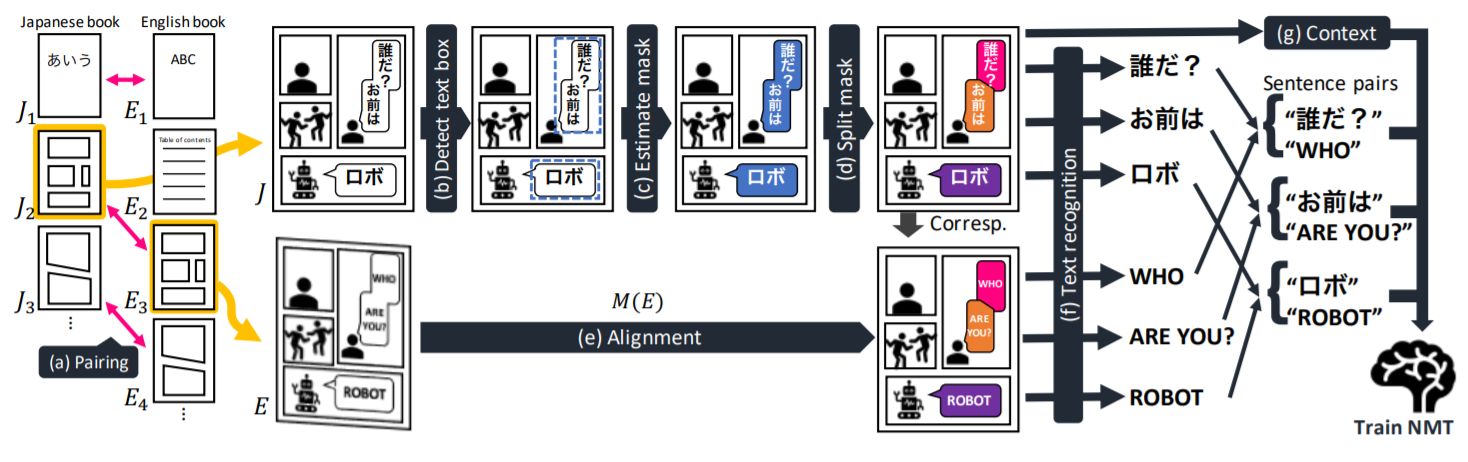
The authors created a PubManga corpus (available by request) and released the OpenMantra corpus dataset. The OpenMantra corpus consists of a parallel NMT training and evaluation dataset in Japanese, English and Chinese with five Japanese manga series across different genres, including fantasy, romance, battle, mystery, and slice of life. In total, the dataset consists of 1593 sentences, 848 frames and 214 pages.
0-day Manga Translations?
Very exciting work! We should be expecting more work in this area and eventually high quality 0-day manga translation releases!
Do check out the paper, the dataset and drop by our Facebook Page or LinkedIn Page to join in the conversation.