
tl;dr Google Colab and Paperspace Gradient both provide Jupyter notebooks with free GPUs in the cloud to code, train and test your ML models. Which is the better option? In this article we compare them. Our final answer is to use both depending on your current ML workloads and requirements.
What is Google Colab and what is Paperspace Gradient?
If we had to pick one particular tool that makes ML easier for everyone, it would be cloud Jupyter notebooks. You can just write code, on any PC with a browser, and execute it in the cloud. You can train both simple and complex ML models, do data science and visualisation, document it and share it with others, all within one simple UI. Both Google Colab and Paperspace Gradient are such notebook-in-the-cloud providers.
| Google Colab | Paperspace Gradient |
|---|---|
| Colaboratory, or “Colab” for short, allows anybody to write and execute arbitrary python code through the browser, and is especially well suited to machine learning, data analysis and education. | Gradient is a suite of tools designed to accelerate cloud AI and machine learning. It includes a powerful job runner, first-class support for containers and Jupyter notebooks, and other language integrations. |
| Colab is a product from Google Research. | Gradient is a product of Paperspace. The Paperspace company came from startup accelerator YCombinator. |
What GPUs do I get for free?
These are the respective runtimes you get for free on each of the platforms:
| Google Colab | Paperspace Gradient | |
|---|---|---|
| GPU | Nvidia K80s, T4s, P4s and P100s | Nvidia M4000 and P5000 GPUs |
| GPU RAM | Up to 16GB | Up to 16GB |
| CPU/Cores | 2x 2.30GHz (Haswell) | 8x vCPU |
| RAM | 12GB (up to 26.75GB) | 30GB |
| Storage | 40GB | 5GB |
| Runtime | Up to 12 hours | Up to 6 hours |
| Sharing | Private/Public | Only Public |
- In Colab there’s no way to choose which GPU you will connect to, you will be disconnected after idle time (90 mins but it may vary), I’ve heard that you may be told in the middle of session that the GPU is unavailable (hasn’t happened to me).
- Colab’s 40GB storage is not persistent, you can mount your Google Drive for persistent storage, if not be sure to download all your files before ending the session. Upgrading your Google Drive for more storage costs a SGD$2.79/per month for 100GB and SGD$3.88/month for 200GB.
- In Gradient you can only use public notebooks in Free tier.
- Tim Dettmers has an excellent article on which GPU to choose for deep learning and detailed GPU performance comparisons. A100s and V100s are by far superior although RTX 3090s give V100s a run for their money.
How much does it cost if I need more?
Unfortunately, Colab Pro is only available in US and Canada at the moment. You can however connect to a local runtime for execution or to a GCP compute engine instance for execution. Pricing depends on the instance you connect to but its generally not a cheap way to run ML workloads, especially if they take more than a few days.
For Gradient, the upgrade options are aplenty. Monthly plans are shown below.
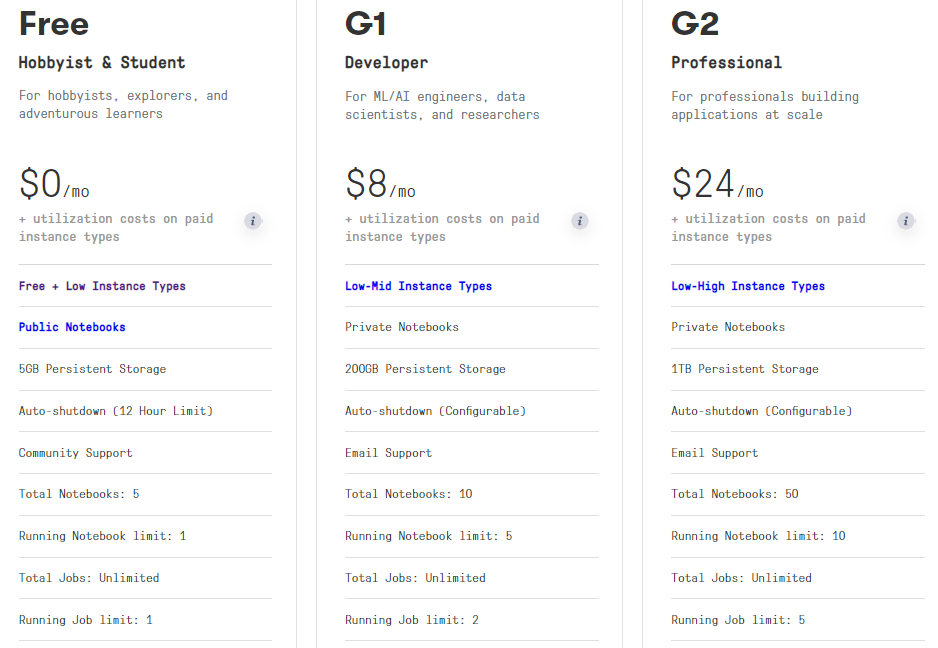
Paid monthly plans allow access to mid and high tier instance tiers of which the following GPU instances are available.
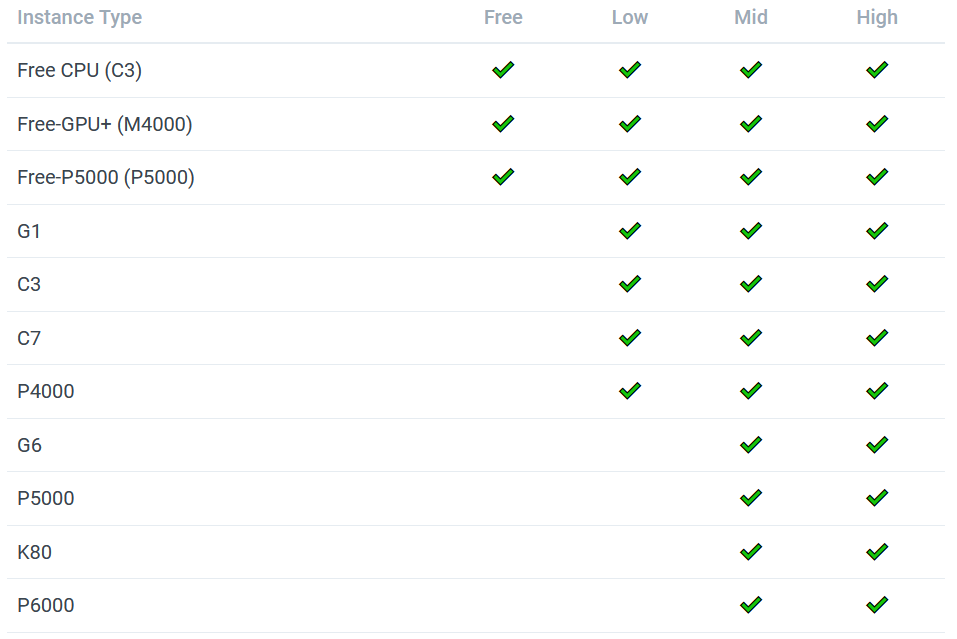
The instance types are described in more detail in Gradient’s documentation, in particular GPU instances.
Feature Comparison
Colab is something of Google’s no-frills take on Jupyter Notebooks. The integration with GCP and Google Drive is helpful if you already use the services.
Gradient on the other hand is focused on making a business of running ML workloads in the cloud. Gradient has other features like a CLI tool, more control of GPU and easier data management services. Gradient’s UI does require a little getting used to but also goes further in supporting end-to-end workflows, deployment and more visibility over your models - something like having a tool like Weights & Biases integrated.
Anyway, here is a comparison of features and links to more information on each of the features.
| Google Colab | Paperspace Gradient | |
|---|---|---|
| Showcase | Super Duper NLP Repo | ML Showcase |
| Github Integration | ✔️ | GradientCI |
| CLI | ❌ | ✔️ |
| Persistent | Google Drive | ✔️ |
| Jupyter Version | Forked | Vanilla |
| Sharing | ✔️ | ✔️ |
| Hyperparmeter Tuning | ❌ | Hyperopt |
| Model Repository | ❌ | ✔️ |
| Deployment | ❌ | ✔️ |
| Projects | ❌ | ✔️ |
| BigQuery Integration | ✔️ | ❌ |
| Metrics Logging | ❌ | ✔️ |
Conclusion
- Free GPUs will help you get started on ML learning quickly. If you’re already a practitioner, they can help you quickly explore notebooks or do training from anywhere.
- There are issues for long running jobs on both platforms free tier (limit of 6 hours for Gradient or 90 minute idle time suspension on Colab)
- There are issues if you need high RAM or multi-GPU, especially if you’re working on NLP, GNNs or on GANs.
- Theoretically you can get better GPUs for free in Colab, but these are randomly assigned and you are never guaranteed which ones you get.
- Both Colab and Paperspace’s Gradient are quite similar in supporting a Jupyter notebook-centric ML workflow. They also allow sharing your notebooks and models quite easily.
- If you need more features to manage your projects, models and deployment instead of just running computations, Gradient is the option.
- Gradient offers a persistent storage, its also faster, however you are only given 5GB of free space (upgrading it to 200GB will cost you USD$8 per month). For Colab you should connect to your Google Drive and upgrade that with Google One (upgrading it to 100GB will cost you SGD$2.79 per month) if you need more storage space.
If you do sign up for Gradient, you can use this referral code which gives you $10 free credit and sends $15 free credit our way.
Also, be sure to check out the top repositories from Singapore on machinelearning.sg.
Other Alternatives
- Deepnote - Supports CPU-based workloads only, basic CPU workloads are free
- BlobCity - $75/month for GPU workloads, basic public CPU workloads are free
- FloydHub - $9/month + $1.20/hr for GPU workloads, basic public CPU workloads are free
- Q Blocks - P2P, $20 package for ~100 GPU hours.
- Vast.ai - $1.40 per V100/hour.
- GPU.land - $0.99 per V100/hour. 2nd lowest besides DataCrunch.io but promises to be more secure and stable than DataCrunch.
- DataCrunch.io - $0.85 per V100/hour. The cheapest GPUs. Hosted in Finland.
- Leader GPU - $1.20 per V100/hour. Based in the Netherlands.
- FloydHub - $4.20 per V100/hour. More expensive than Azure, AWS and GCP.
- Lambda Cloud - $1.50 per V100/hour.
ML Contests has a cloud GPU comparison table.