tl;dr We feature 10 of the top Computer Vision (CV) code repositories from Singapore. These include popular
implementations of YOLO3, EfficientDet, DeepLab, FaceBoxes and other models ranging from activity recognition to eye tracking. The ranking is decided based on the total Github stars of the repositories.
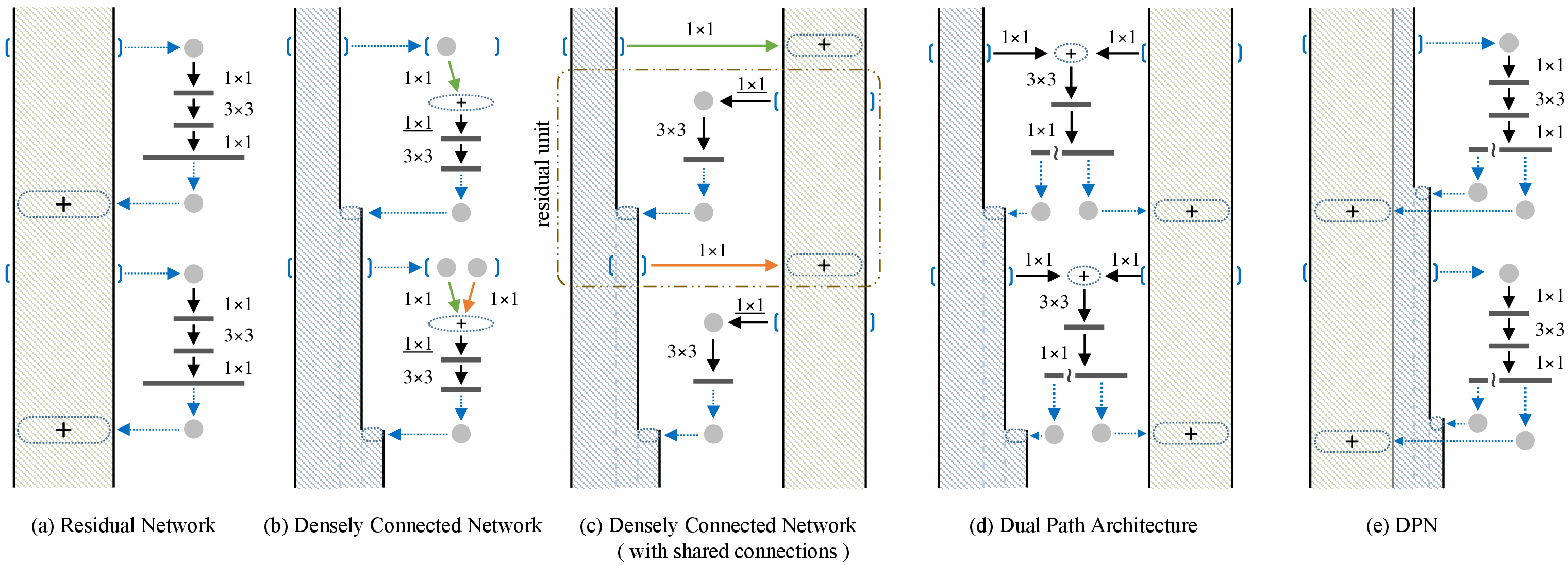
This repository contains the code and trained models of Dual Path Networks which won the 1st place in Object Localization
Task in ILSVRC 2017, and was a Top 3 team with on all competition tasks (Team: NUS-Qihoo_DPNs).
PointPillars is a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical
columns (pillars). While the encoded features can be used with any standard 2D convolutional detection architecture,
we further propose a lean downstream network. Extensive experimentation shows that PointPillars outperforms previous
encoders with respect to both speed and accuracy by a large margin. Despite only using lidar, our full detection
pipeline significantly outperforms the state of the art, even among fusion methods, with respect to both the 3D and
bird’s eye view KITTI benchmarks.
A Python (2 and 3) library that provides a webcam-based eye tracking system.
It gives you the exact position of the pupils and the gaze direction, in real time.
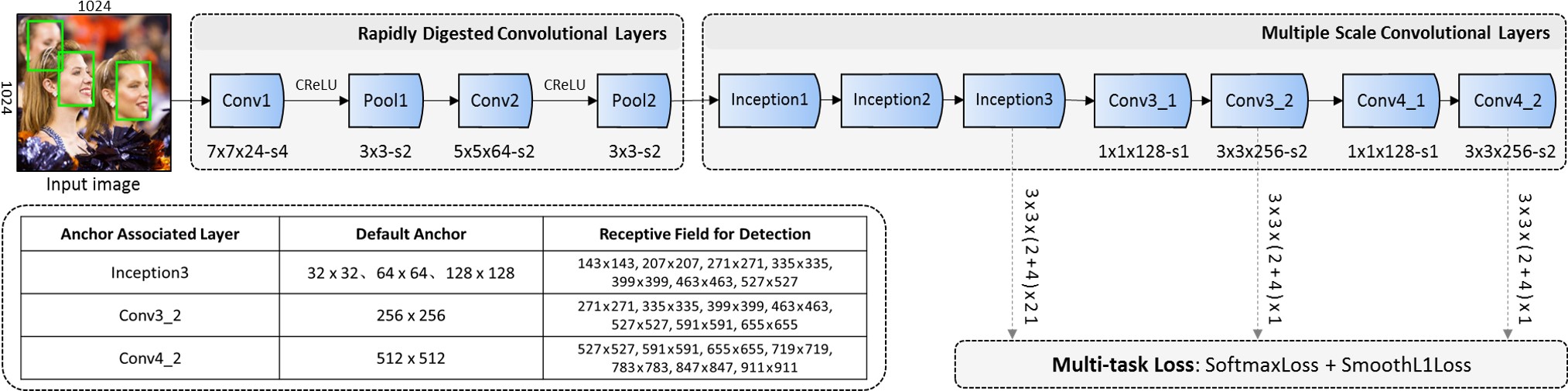
The architecture of FaceBoxes. Retrieved from Github.
A PyTorch implementation of the FaceBoxes: A CPU Real-time Face Detector with High Accuracy.
The original was implemented in caffe. FaceBoxes is a novel CPU-based face detector,
with superior performance on both speed and accuracy. The speed of FaceBoxes is invariant to the number of faces.
The nuScenes dataset is a public large-scale dataset for autonomous driving developed by the team at Motional
(formerly nuTonomy). The dataset is meant to support public research into computer vision and autonomous driving.
The dataset contains 1000 driving scenes in Boston and Singapore, two cities that are known for their dense traffic and
highly challenging driving situations. The scenes of 20 second length are manually selected to show a diverse and
interesting set of driving maneuvers, traffic situations and unexpected behaviors. To facilitate common computer vision
tasks, such as object detection and tracking, the dataset contains annotations for 23 object classes with accurate
3D bounding boxes at 2Hz over the entire dataset.
This repository contains the devkit of the nuImages and nuScenes dataset.
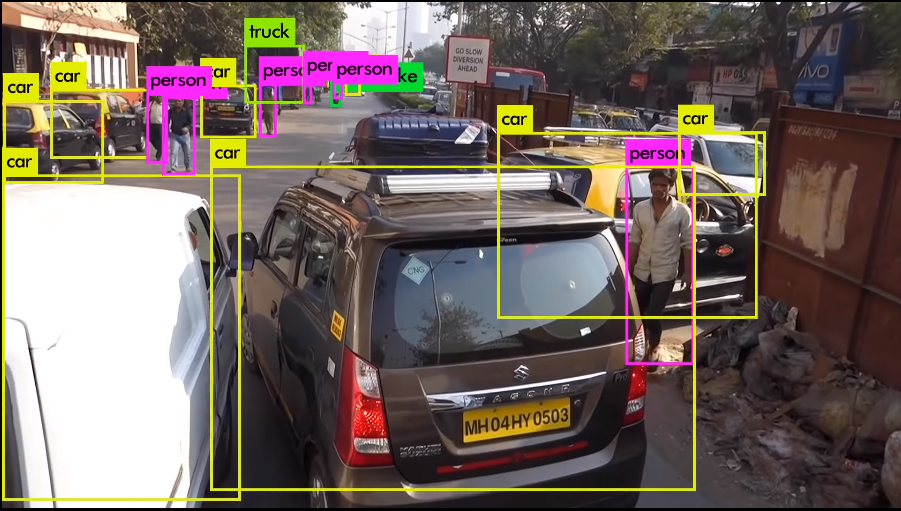
Object bounding boxes on video footage as predicted by YOLO3. Retrieved from the official YOLO site.
A Computer Vision repository with code for training and evaluation of a YOLO3 model for the Object Detection task.
YOLO, You Only Look Once, is a state-of-the-art, real-time object detection model.
Its claim to fame is its extremely fast and accurate and you can trade-off speed and accuracy without re-training
by changing the model size. Multi-GPU training is also implemented.
Some results of the deep labelling model on various datasets. Retrieved from Github.
A computer vision repository which started with an early PyTorch implementation (circa 2018) of DeepLab-V3-Plus (in PyTorch 0.4.1).
DeepLab is a series of image semantic segmentation models whose latest version, v3+, is state-of-art on the semantic segmentation task.
It can use Modified Aligned Xception and ResNet as backbone.
The authors train DeepLab V3 Plus using Pascal VOC 2012, SBD and Cityscapes datasets. Pre-trained models on ResNet,
MobileNet and DRN are provided.