tl;dr We feature 10 of the top Natural Language Processing (NLP) code repositories on Github from Singapore.
The ranking is decided based on the total stars (stargazer count) of the repositories.
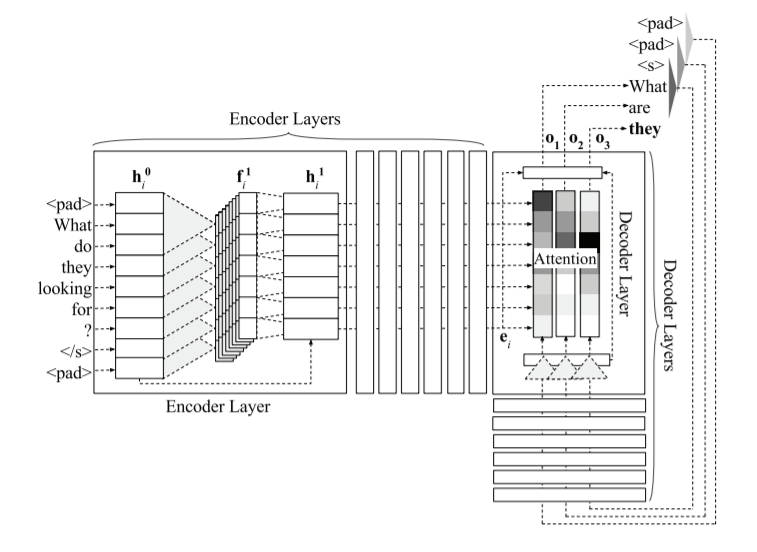
10. A Multilayer Convolutional Encoder-Decoder Neural Network for Grammatical Error Correction#
Architecture of the multilayer convolutional model with seven encoder and seven decoder layers. Retrieved from the official paper.
Code and model files for the paper: “A Multilayer Convolutional Encoder-Decoder Neural Network for Grammatical Error
Correction” (Published at AAAI-18).
The authors improve the automatic correction of grammatical, orthographic, and collocation errors in text using a
multilayer convolutional encoder-decoder neural network.
Project Insight: NLP as a Service. Retrieved from Github.
Project Insight is an NLP as a service project with a frontend UI (streamlit) and backend server (FastApi)
serving transformers models on various downstream NLP task.
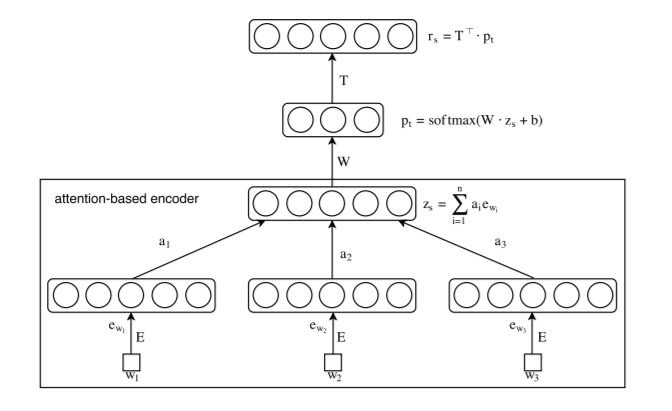
8. An Unsupervised Neural Attention Model for Aspect Extraction#
An example of an Attention-based Aspect Extraction (ABAE) structure. Retrieved from the official paper.
Code for the ACL2017 paper “An Unsupervised Neural Attention Model for Aspect Extraction”.
Aspect extraction is one of the key tasks in sentiment analysis. It aims to extract entity aspects on which opinions
have been expressed. For example, in the sentence “The beef was tender and melted in my mouth”, the aspect term is “beef”.
Experimental results on real-life datasets demonstrate that our approach discovers more meaningful and coherent aspects,
and substantially outperforms baseline methods on several evaluation tasks.
Aspect-Based Sentiment analysis (ABSA) can then be performed on the set of aspects in the downstream task.
NLP scientist at Alibaba DAMO Academy. Ph.D. from NUS.
Language
Stars
Forks
Open Issues
Python
265
107
16
7. ✍🏻 gpt2-client: Easy-to-use TensorFlow Wrapper for GPT-2 🤖 📝#
Exploring GPT-2 models in less than five lines of code. Retrieved from Github.
GPT-2 is a Natural Language Processing model developed by OpenAI for text generation. The model has 4 versions -
117M, 345M, 774M, and 1558M - that differ in terms of the amount of training data fed to it and the number of parameters
they contain.
gpt2-client is a wrapper around the original gpt-2 repository that features the same functionality but with more
accessiblity, comprehensibility, and utilty. You can play around with all four GPT-2 models in less than five lines of code.
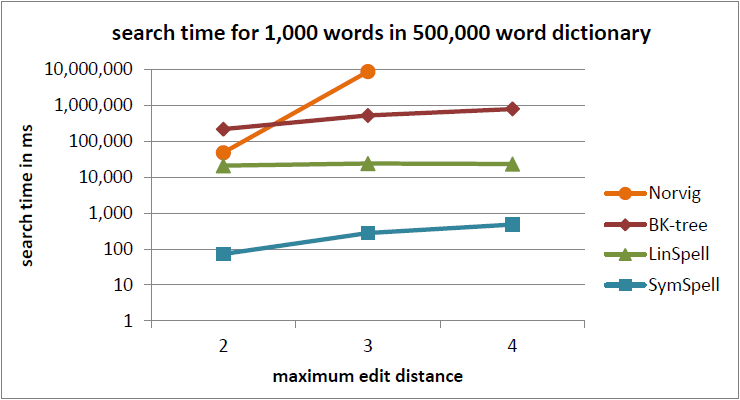
Performance of SymSpell (C# version) vs other edit distance/spell check algorithms. Retrieved from Github.
A Python port of SymSpell, a 1 million times faster
spelling correction & fuzzy search through Symmetric Delete spelling correction algorithm.
The Symmetric Delete spelling correction algorithm reduces the complexity of edit candidate generation and dictionary
lookup for a given Damerau-Levenshtein distance. It is six orders of magnitude faster (than the standard approach with
deletes + transposes + replaces + inserts) and language independent.
4. Textstat: Python Package to Calculate Readability Statistics of Text#
Example code to use the Textstat library.
Textstat is an easy to use library to calculate statistics from text. It helps determine readability, complexity, and grade level.
It supports various statistics including: Flesch Reading Ease Score, Flesch-Kincaid Grade Level, Fog Scale (Gunning FOG Formula),
SMOG Index, Automated Readability Index, Coleman-Liau Index, Linsear Write Formula and the Dale-Chall Readability Score.
Data Scientist | Natural Language Processing + Machine Learning Enthusiast | Data Stories + Visuals | Programmer + Coder | at H2O.ai
Language
Stars
Forks
Open Issues
Python
554
107
18
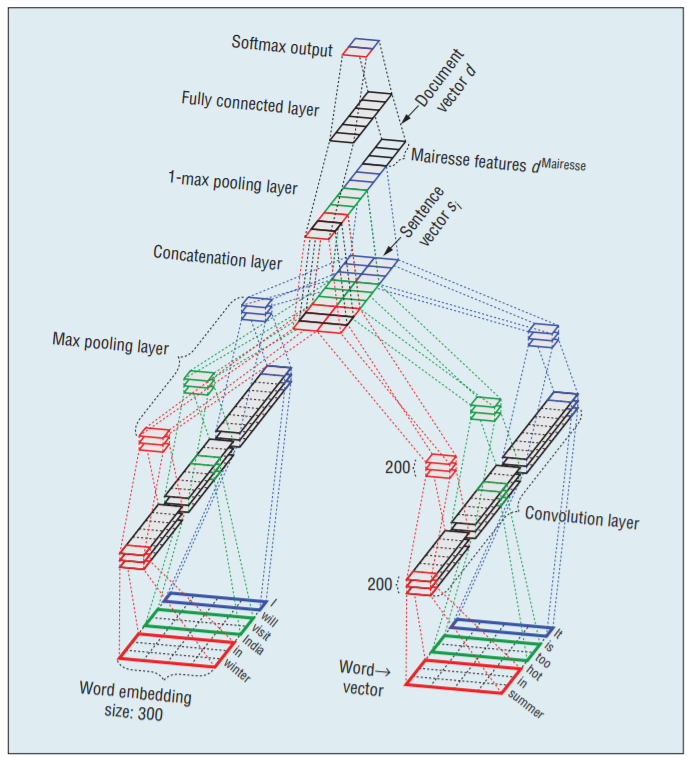
3. Sentiment analysis on tweets using Naive Bayes, SVM, CNN, LSTM, etc.#
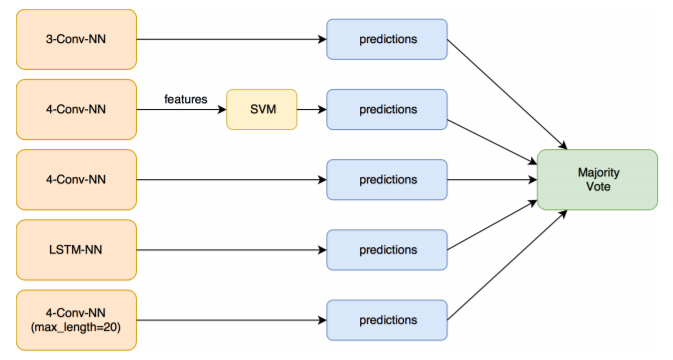
Flowchart of the majority voting ensemble used. Retrieved from the official report.
Sentiment classification on twitter dataset. The authors use a number of machine learning and deep learning methods to
perform sentiment analysis (Naive Bayes, SVM, CNN, LSTM, etc.). The authors finally use a majority vote ensemble method
with 5 of our best models to achieve the classification accuracy of 83.58% on kaggle public leaderboard.
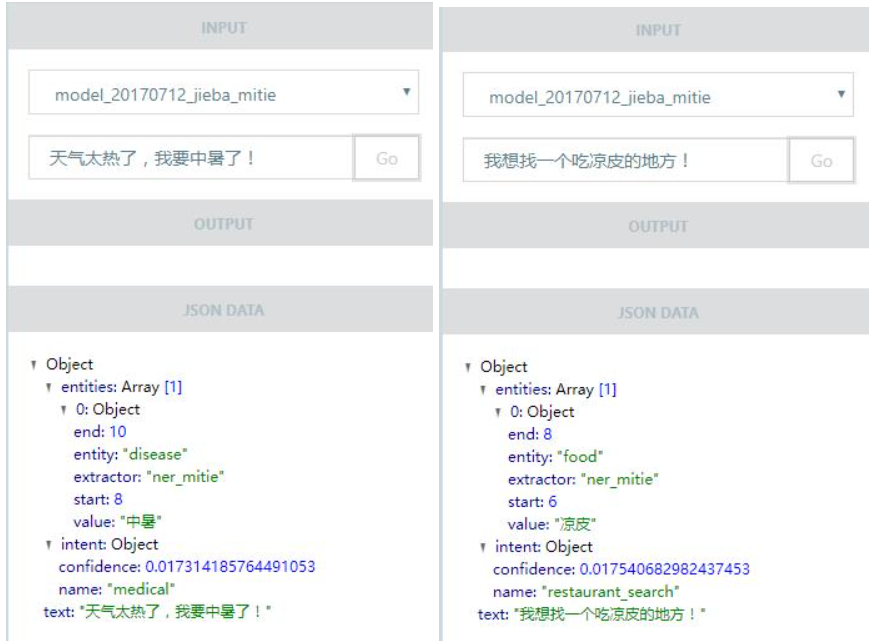
Natural Language Understanding outputs from the RASA NLU Chinese model. Retrieved from Github.
A fork from the RASA (contextual AI assistant/chatbot) NLU repository. Focused on the Natural Language Understanding (NLU)
task (中文自然语言理解).
Turn a chinese natural language sentence/utterance into structured data.
1. Chinese Named Entity Recognition and Relation Extraction#
Visualization of 3x3, 7x7 and 15x15 receptive fields produced by 1, 2 and 4 dilated convolutions by the IDCNN model.
An NLP repository including state-of-art deep learning methods for various tasks in chinese/mandarin language (中文):
named entity recognition (NER/实体识别), relation extraction (RE/关系提取) and word segmentation.